Assuming that the government would be able to finance the stimulus bill by selling $819B worth of Treasury bonds at let’s say 4.5% to the Chinese government and others the yearly interest WE will pay on those bonds is just about $36.9 billion for a 30 year total of $1,105,650,000,000 – that would be about $1.1 trillion dollars in case you are having trouble reading that number. And just in case you are trying to envision what $1 trillion dollars look like check this out: http://www.cnn.com/2009/LIVING/02/04/trillion.dollars/index.html
So, what does this have to do with SQL Server tools? Nothing really other than these numbers are so amazingly big that it is hard to just ignore them and focus on our job which is to build awesome tools for SQL Server database administrators and developers.
Thursday, January 29, 2009
Wednesday, January 28, 2009
Another presentation on RSS Reporter
Chad Miller did another presentation at the SQL Saturday Tampa 2009 focused on RSS enabling System Administration information - utilizing RSS Reporter to automate the daily DBA checklist by aggregating job status information from across multiple SQL Servers and databases. More details can be found on Chad's blog: http://chadwickmiller.spaces.live.com/blog/cns!EA42395138308430!267.trak
Monday, January 19, 2009
Deploying database schema changes to hundreds of clients
This post is directed to software publishers who have published software that uses SQL Server on the back end. Here is a simple scenario you run into: you release the software and within a couple of months you have successfully deployed it to tenths of customers. In the meantime you have discovered a flaw on a stored procedure which needs to be changed, you want to add a couple of reports for which you need to add a couple of new supporting views, a column on a table needs to be changed from varchar(50) to varchar(100) etc. – you get the picture. The question is: how do you make those changes on all those customers’ sites? You could send them a change script that will alter and add those objects in the database but a lot of the customers don’t know anything about SQL Server and don’t won’t to deal with those scripts. Furthermore, if this is not the first iteration of changes and the customers are using different versions of your database the script you send must be customized for each version. The main point here is that sending the customers a t-sql change script and asking them to apply it is generally not going to work.
So, what do you do? Well, you use xSQL Builder which was designed to alleviate this kind of trouble. xSQL Builder is extremely easy to use but at the same time, if your scenario is more complicated it gives you all the flexibility to customize it to best fit your needs. How does it work? You go through a simple wizard that takes no more than a couple of minutes and allows you to choose the source or “master” database which you want to deploy to your customers, set a few parameters and generate an executable package that you can then send to your clients. The client runs the executable which compares the embedded schema of the source/master database with the client’s version of the database, generates a synchronization script, executes the script and emails you the results. Now, you have to admit that is a cool and extremely efficient way to deploy your database schema changes.
You can download your copy of xSQL Builder from: http://www.xsql.com/download/sql_database_deployment_builder/
So, what do you do? Well, you use xSQL Builder which was designed to alleviate this kind of trouble. xSQL Builder is extremely easy to use but at the same time, if your scenario is more complicated it gives you all the flexibility to customize it to best fit your needs. How does it work? You go through a simple wizard that takes no more than a couple of minutes and allows you to choose the source or “master” database which you want to deploy to your customers, set a few parameters and generate an executable package that you can then send to your clients. The client runs the executable which compares the embedded schema of the source/master database with the client’s version of the database, generates a synchronization script, executes the script and emails you the results. Now, you have to admit that is a cool and extremely efficient way to deploy your database schema changes.
You can download your copy of xSQL Builder from: http://www.xsql.com/download/sql_database_deployment_builder/
Thursday, January 15, 2009
Wrap your insert, update and delete statements on a transaction – ALWAYS
The main objective of a transaction is to ensure that either every statement within that transaction is executed successfully or none of them. So, you would logically wrap in one transaction related statements that should be executed together. A classic example is that of transferring money from one account to another – the action of subtracting the money from account A must happen together with the action of adding that same amount of money to account B (either both or none) otherwise, if let’s say the system crashed right after subtracting the money from account A and before adding them to account B the money will disappear! So, great, when one understands this a legitimate question comes to mind – what’s the point of wrapping a single statement in a transaction?
Well, we are humans and as such we are prone to making mistakes, sometimes, big and costly mistakes so, wouldn’t it be nice to “erase” our mistakes when we realize that? That’s what a simple Begin Transaction statement provides us – the ability to rollback our mistakes. How does one realize that he made a mistake – the first indicator is the “number of rows effected” which SQL Server reports – if that number is larger than you expected then maybe you made a mistake on your statement. How else can I tell? The cool thing is that SQL Server will let you read the uncommitted rows and see what your statement did - so you can issue a select and review the rows you just updated for example. If you do realize that you made a mistake you simply issue a rollback and all is good – it is like it never happened. If you are sure your statement did what you intended it to do then you issue a commit transaction and the changes you just made become permanent.
So again, be diligent and wrap every update, delete or insert statement in a begin transaction / rollback / commit transaction. It is much better to be safe then sorry!
Applies to: SQL Server, SQL Server Mangement Studio, Query Analyzer
Well, we are humans and as such we are prone to making mistakes, sometimes, big and costly mistakes so, wouldn’t it be nice to “erase” our mistakes when we realize that? That’s what a simple Begin Transaction statement provides us – the ability to rollback our mistakes. How does one realize that he made a mistake – the first indicator is the “number of rows effected” which SQL Server reports – if that number is larger than you expected then maybe you made a mistake on your statement. How else can I tell? The cool thing is that SQL Server will let you read the uncommitted rows and see what your statement did - so you can issue a select and review the rows you just updated for example. If you do realize that you made a mistake you simply issue a rollback and all is good – it is like it never happened. If you are sure your statement did what you intended it to do then you issue a commit transaction and the changes you just made become permanent.
So again, be diligent and wrap every update, delete or insert statement in a begin transaction / rollback / commit transaction. It is much better to be safe then sorry!
Applies to: SQL Server, SQL Server Mangement Studio, Query Analyzer
Wednesday, January 14, 2009
SQL Server Query Governor way off on its estimates!
First of all if you are looking for information on how to set the query governor cost limit option you can go directly to the source: http://msdn.microsoft.com/en-us/library/ms190419(SQL.90).aspx or to any of the tenths of blogs that seem to have replicated this information word for word.
So, here is the scenario: as a diligent DBA you audit a SQL Server you just took over and you realize that the query governor cost limit is set to 0 which means in essence that as far as the query governor is concerned any queries can run on the server for as long as they need to run. That’s not good so you go ahead and set a high limit to start with, let’s say 300 seconds. Your thinking is that if a query that is estimated to run for more than 5 minutes ever comes across it should be stopped dead on its tracks before hundreds of calls from angry users reach your desk. To your surprise 5 minutes after you have set that limit you get a call from Jane Doe – she has seen this strange message on her screen she never saw before “you can’t execute this query because it is estimated to take 450 seconds”. Jane assures you that the report she is running usually runs in 5 to 10 seconds!
You go ahead and raise the limit to 500 seconds – Jane runs the report and sure enough the report takes less than 6 seconds! Something is not right – why is the query optimizer so grossly overestimating the time this query will take to run?
The answer is simple indeed – remember the query optimizer is estimating - estimates are made based on available information and if the available information is either missing or not accurate than the estimate won’t be accurate. The information that the query optimizer uses is in the statistics that SQL Server maintains and that is where you need to look. So, check it Auto Create Statistics is on first – if not no then you either need to turn it on or manually create the statistics the optimizer needs for estimating this query (this is the case when the necessary statistics information may be missing). Second check if Auto Update Statistics is on – if not you may need to update the stats to enable the query optimizer to produce a more accurate estimate.
Furthermore, you may find that all is in order that is no statistics are missing and the stats are up to date and yet the estimate is wrong! Try forcing a recompile of the query in question and see what happens. What may have happened is that SQL Server is using a cashed plan that was optimized for the “wrong” parameter values – that is values which are not good representatives of the dataset and based on that plan it is estimating that 10,000 rows will be returned from table a when in fact in 90% of the cases the number of rows returned from table a on that query is under 1000. By forcing a recompile of the query you are forcing SQL Server to re-evaluate and possibly pick a better plan this time based on new parameter values.
The objective of using the query governor cost option is to prevent “stupid” queries from degrading the system performance and not to prevent legitimate queries from running. So you may be forced to raise the limit but you should look at that as a temporary measure until you have dealt with the legitimate queries by taking the above mentioned actions as well as optimizing the query itself. Then, you should go back and start gradually lowering the query governor cost limit.
So, here is the scenario: as a diligent DBA you audit a SQL Server you just took over and you realize that the query governor cost limit is set to 0 which means in essence that as far as the query governor is concerned any queries can run on the server for as long as they need to run. That’s not good so you go ahead and set a high limit to start with, let’s say 300 seconds. Your thinking is that if a query that is estimated to run for more than 5 minutes ever comes across it should be stopped dead on its tracks before hundreds of calls from angry users reach your desk. To your surprise 5 minutes after you have set that limit you get a call from Jane Doe – she has seen this strange message on her screen she never saw before “you can’t execute this query because it is estimated to take 450 seconds”. Jane assures you that the report she is running usually runs in 5 to 10 seconds!
You go ahead and raise the limit to 500 seconds – Jane runs the report and sure enough the report takes less than 6 seconds! Something is not right – why is the query optimizer so grossly overestimating the time this query will take to run?
The answer is simple indeed – remember the query optimizer is estimating - estimates are made based on available information and if the available information is either missing or not accurate than the estimate won’t be accurate. The information that the query optimizer uses is in the statistics that SQL Server maintains and that is where you need to look. So, check it Auto Create Statistics is on first – if not no then you either need to turn it on or manually create the statistics the optimizer needs for estimating this query (this is the case when the necessary statistics information may be missing). Second check if Auto Update Statistics is on – if not you may need to update the stats to enable the query optimizer to produce a more accurate estimate.
Furthermore, you may find that all is in order that is no statistics are missing and the stats are up to date and yet the estimate is wrong! Try forcing a recompile of the query in question and see what happens. What may have happened is that SQL Server is using a cashed plan that was optimized for the “wrong” parameter values – that is values which are not good representatives of the dataset and based on that plan it is estimating that 10,000 rows will be returned from table a when in fact in 90% of the cases the number of rows returned from table a on that query is under 1000. By forcing a recompile of the query you are forcing SQL Server to re-evaluate and possibly pick a better plan this time based on new parameter values.
The objective of using the query governor cost option is to prevent “stupid” queries from degrading the system performance and not to prevent legitimate queries from running. So you may be forced to raise the limit but you should look at that as a temporary measure until you have dealt with the legitimate queries by taking the above mentioned actions as well as optimizing the query itself. Then, you should go back and start gradually lowering the query governor cost limit.
Monday, January 12, 2009
Why is SQL Server scanning the clustered index when I have an index on the column I am filtering on?
I ran into a very simple SQL Server performance related question the other day. A puzzled DBA was staring at a simple query “SELECT * FROM table1 WHERE col_n = x”. Since this was a fairly common query that was executed very frequently he had appropriately created an index on col_n. Yet, for some reason SQL Server was simply ignoring the index on col_n and instead scanning the clustered index. So the puzzling question on this DBAs mind was “why is SQL Server scanning the table? Isn’t the SQL Server Query Optimizer smart enough to see that it will be more efficient to use the col_n index?
The answer lies in the fact that the SQL Server Query Optimizer is smarter than that (albeit not as smart as I wish it would be). You see, when deciding on a particular execution plan the Query Optimizer has to use an actual value for the parameter x to estimate the number of rows that will be returned on each step. It further assumes that the rows you are looking for are randomly distributed and that it will need to do a page read for every row being returned in addition of the reads it needs to do on the index pages. Depending on this number it makes a determination whether it will be more efficient to just scan the whole table and pull out the rows it needs or go to the col_n index first to get a list of addresses and then go and pull those rows.
So, now that we know why should we just leave it there since it appears that SQL Server is correctly picking the most efficient path? Not so fast! Remember all that evaluation is being done based on a certain value of parameter x. It could be that for most of the values of parameter x scanning the table is more efficient. In that case you can simply drop the index on col_n if it is not needed for any other queries and leave it at that. However, it could be that for 99% of the possible values of x it would be a lot more efficient to utilize the col_n index – it just so happened that unfortunately when generating the plan the value of x happened to fall on that 1% for which scanning is more efficient. In this case you have to options:
The answer lies in the fact that the SQL Server Query Optimizer is smarter than that (albeit not as smart as I wish it would be). You see, when deciding on a particular execution plan the Query Optimizer has to use an actual value for the parameter x to estimate the number of rows that will be returned on each step. It further assumes that the rows you are looking for are randomly distributed and that it will need to do a page read for every row being returned in addition of the reads it needs to do on the index pages. Depending on this number it makes a determination whether it will be more efficient to just scan the whole table and pull out the rows it needs or go to the col_n index first to get a list of addresses and then go and pull those rows.
So, now that we know why should we just leave it there since it appears that SQL Server is correctly picking the most efficient path? Not so fast! Remember all that evaluation is being done based on a certain value of parameter x. It could be that for most of the values of parameter x scanning the table is more efficient. In that case you can simply drop the index on col_n if it is not needed for any other queries and leave it at that. However, it could be that for 99% of the possible values of x it would be a lot more efficient to utilize the col_n index – it just so happened that unfortunately when generating the plan the value of x happened to fall on that 1% for which scanning is more efficient. In this case you have to options:
- simply force SQL Server to dispose the bad plan that it has cashed and generate a new one; OR
- use a HINT to force SQL Server to use the index. The danger with this however is that with time as the data changes the use of that index may not be optimal so I would recommend that you avoid using HINTS whenever possible and let SQL Server do its job.
One last note: it is often not necessary to return all the columns – in other words instead of SELECT * FROM table1 WHERE col_n = x you may only need to return a couple of columns like SELECT col_1, col_2 FROM table1 WHERE col_n = x in which case it could be worth it to include col_1 and col_2 in the col_n index. That way SQL Server would not need to go to the table at all but instead get all it needs from the index pages. In certain scenarios where you have a rarely updated but very frequently queried table the above approach of including other columns in the col_n index may make sense even if the query returns all the columns.
SQL Server search stored procedures
Anyone who works with SQL Server has at one point or another faced the simple question: “how can I find all stored procedures that reference a given table?”, or “how can I find all the objects in the database the definition of which contains a certain word or phrase?”. While SQL Server makes those tasks relatively easy those are still time consuming and when done on an ad-hoc bases chances of missing or forgetting something are relatively high.
The good news is: you don’t have to struggle with this when there is a really cool and completely free tool called xSQL Object Search available. So how does xSQL Object Search work? Very simple:
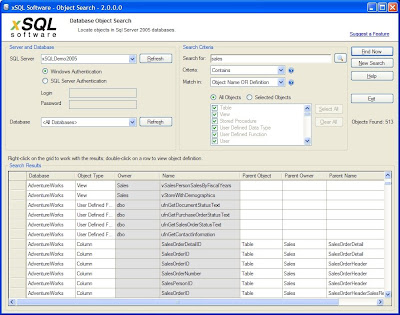
xSQL Object Search is a free tool and you can download it from: http://www.xsql.com/download/sql_server_object_search/
Applies to:
SQL Server search tables
SQL Server search views
SQL Server search stored procedures
SQL Server search triggers
SQL Server search functions
The good news is: you don’t have to struggle with this when there is a really cool and completely free tool called xSQL Object Search available. So how does xSQL Object Search work? Very simple:
- You connect to the server you are interested on
- Choose to search in a certain database or All Databases on that server
- Define your search criteria
- What are you looking for
- How do you want to search (exact match, contains, starts with, ends with, sql server expression, regular expression)
- Choose where do you want to look - the object name, object definition, or both?
- Finally choose which object types you wish to search (all objects or just certain types of objects like stored procedures, views, tables, triggers etc.)
- Click on Find Now (see the screen shot below
{kind=link}
xSQL Object Search is a free tool and you can download it from: http://www.xsql.com/download/sql_server_object_search/
Applies to:
SQL Server search tables
SQL Server search views
SQL Server search stored procedures
SQL Server search triggers
SQL Server search functions
Tuesday, January 6, 2009
Free SQL data compare tool
There are many scenarios in which someone working with SQL Server may need to find out what the data differences are between two databases or just two tables. Furthermore, it is often necessary to synchronize the data, that is, make the data in the target database the same as the data in the source database or vice versa. That’s where xSQL Data Compare comes in – it is a tool that was designed specifically for this purpose. It comes as part of the xSQL Bundle package and just like in the case of xSQL Object chances are you won’t have to ever pay a dime for it.
The xSQL Data Compare licensing works exactly the same way as the licensing of xSQL Object described in detail on yesterday’s post here.
The xSQL Data Compare licensing works exactly the same way as the licensing of xSQL Object described in detail on yesterday’s post here.
Monday, January 5, 2009
Free SQL Compare tools for SQL Server
If you are looking for a free schema compare tool that allows you to compare and synchronize the schemas of two SQL Server databases, like your development database with the production database, then xSQL Object is the tool for you. Not only is it one of the best tools in the market (don’t take our word for it – give it a try and you will see for yourself) but what’s unmatched in the industry is the way our licensing works. I will give you the details below but the end result is that most of our users enjoy using xSQL Object completely free. Here is how our licensing works:
- everyone downloads the same xSQL Comparison Bundle package that includes xSQL Object and xSQL Data Compare;
- for the first two weeks the applications function as if you had purchased a professional license;
- after the first two weeks the licensing module first checks the edition of the databases you are comparing:
- if both databases are SQL Server Express edition then you see no difference – works the same as before;
- if one of the databases in the comparison is something other than SQL Server Express then the licensing module checks the number of objects in that database (number of tables, stored procedures, views, functions)
- if the number of objects is within the limits of what we call the Lite Edition then again the application works and you don’t see any difference;
- if the number of objects is greater than those limits then you are kindly notified that to compare and sync that database you need to acquire a license. Well, someone has to pay for all that development effort that goes into our products :)
Subscribe to:
Comments (Atom)